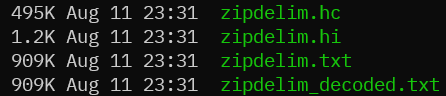
This is a console application that allows a user to input a text file and have it losslessly compressed using Huffman coding. A user can input a file and get back 2 files, being the “decoding dictionary”, and the compressed file. Above, the .txt files are the uncompressed versions, the .hc file is the compressed file, and the .hi is the decoding dictionary. Notice how the sizes of the compressed file is about half the size of the original. The user can then use those two files to decompress the encoded file back into the original.
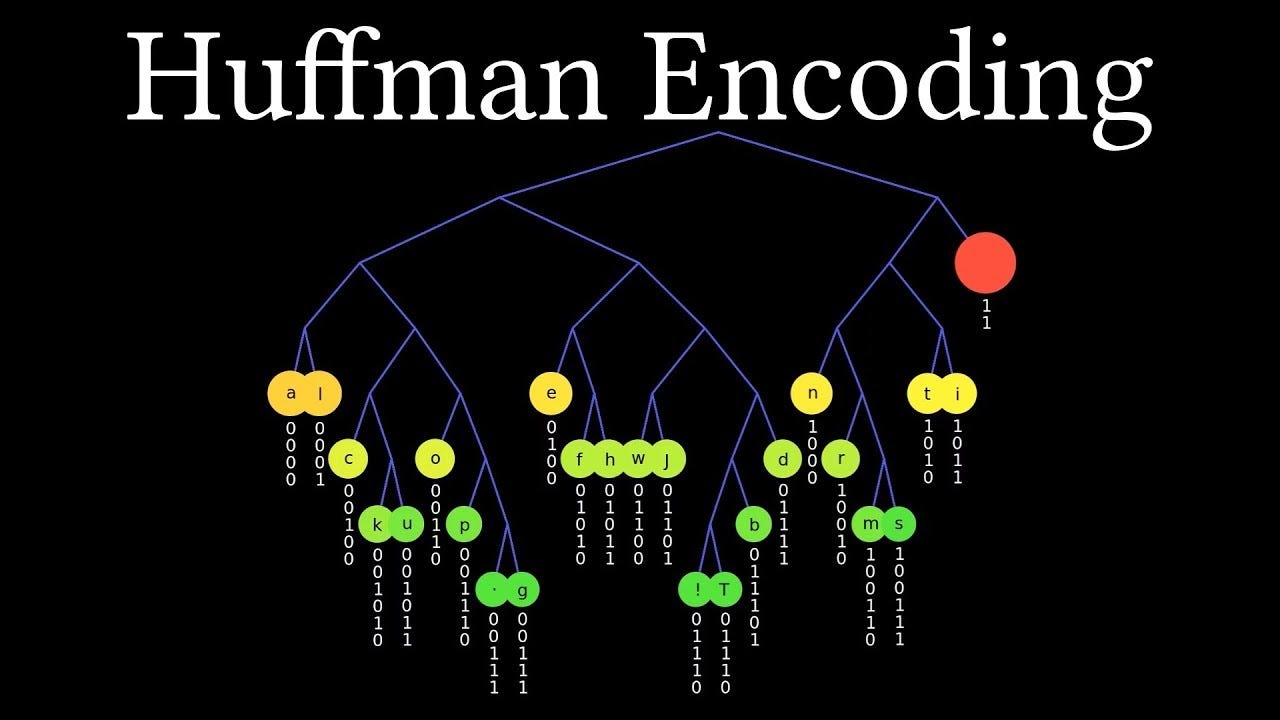
This works by counting the frequency of characters in the original file, and creating a shorter, bit-wise representation of the characters. Instead of each char taking up 8 bits, they can take up fewer bits, while the less frequently used ones can take up more. To achieve this in an efficient runtime, I use a binary search tree where 1 represents going left, and 0 represents going right. This allows even large text files to be compressed and decompressed very quickly.